Multimodal Alignment for LiDAR and Image Data
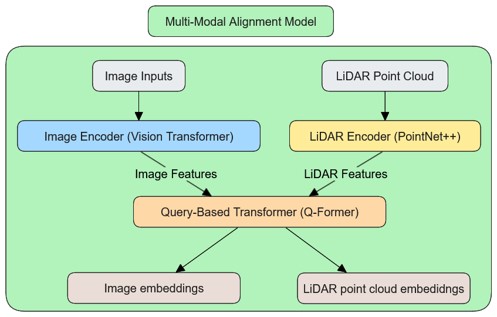
Overview: This project focuses on aligning multimodal data, LiDAR point clouds and RGB images to enhance perception in autonomous systems. Inspired by the Q-Former architecture from BLIP-2, the proposed model integrates a query-based transformer module that aligns spatial relationships between these two modalities, generating shared scene-level embeddings in a unified feature space.
GitHub Repository: View Source Code on GitHub
Key Features:
- Pretrained Encoders: Utilizes Vision Transformers (ViT) for image feature extraction and PointNet++ for LiDAR point cloud encoding.
- Query-Based Transformer (Q-Former): Learns to align embeddings from both modalities, ensuring robust multimodal feature fusion.
- Embedding Alignment: Optimized using cosine similarity loss to ensure embeddings from the same scene are highly similar, improving sensor fusion.
- Training on KITTI Dataset: Evaluated on the widely-used KITTI dataset, demonstrating the model’s effectiveness in multimodal alignment.
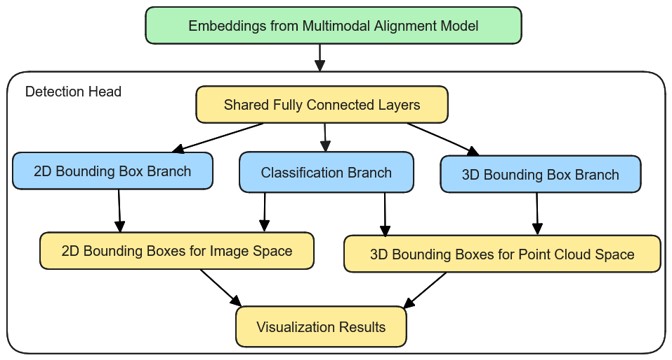
- Object Detection Extension: A detection head was integrated to localize objects in both 2D (image) and 3D (LiDAR), paving the way for future applications in autonomous perception.
Results and Impact
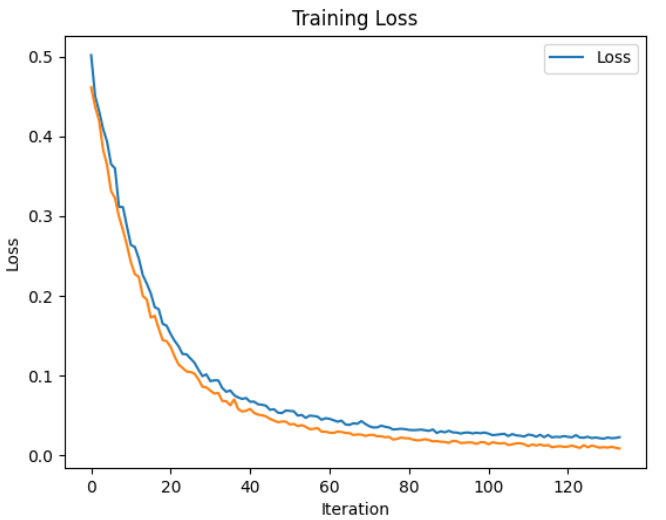
Experiments showed that the model successfully aligns multimodal embeddings, making it useful for autonomous driving and robotic perception tasks. Through dropout regularization and hyperparameter tuning, the model achieved stable performance despite computational constraints.
Technlogies used:
- Deep Learning: PyTorch, Transformers, Vision Transformers (ViT), PointNet++
- Optimization: AdamW, Cosine Similarity Loss, Open3D
- Dataset: KITTI
- Hardware: NVIDIA L40s GPUs (48GB VRAM) via Lightning cloud GPUsli>
This project contributes to advancing multimodal sensor fusion techniques, helping autonomous systems achieve more accurate and robust scene understanding.